Über uns
Lerne uns kennen
Bei robots.txt handelt es sich um eine Datei, welche die Verzeichnisse deiner Website enthält. Diese wird verwendet, um Google mitzuteilen, welche Teile deiner Website gecrawlt werden dürfen und damit indexiert werden sollen. Gleichzeitig kannst du in der txt Datei auch festlegen, welche Seiten nicht durchsucht werden dürfen. Diese Datei ist somit essenziell, wenn du deine Website für SEO optimieren möchtest.
In diesem Artikel lernst du, wie sich eine solche Datei zusammensetzt, wie sie funktioniert und wie du diese selbst erstellen und verwenden kannst.
Inhaltsverzeichnis
Robots.txt ist eine einfache Textdatei, welche im Root Verzeichnis der Website abgelegt werden muss, die dem Robots Exclusion Standard Protokoll entspricht. Suchmaschinen wie Google crawlen Websites nach dieser Datei, um zu definieren, für welche Suchbegriffe welche Seiten erscheinen sollen.
Diese wird oft verwendet, um Crawling-Traffic zu verwalten und gegebenenfalls auszuschliessen, wenn deine Website mit Anfragen überlastet ist. Ebenfalls können gefilterte Inhalte ausgeschlossen werden, da diese einzelne Seiten sind und so als Duplikate gelten könnten, was aus SEO-Sicht ungünstig ist.
Sie ist dagegen nicht geeignet, wenn du gewisse Dateien für die Öffentlichkeit nicht zugänglich machen möchtest. In diesem Fall solltest du diese besser durch ein Passwort schützen.
Wenn du keine oder eine leere robots.txt Datei auf deiner Website hast, bedeutet das, dass Suchmaschinen deine gesamte Seite crawlen dürfen.
Crawler sind Programme, die automatisch die Verzeichnisse und Inhalte deiner Website durchsuchen.
Die robots.txt Datei enthält Informationen darüber, welche Bereiche einer Website von Suchmaschinen gecrawlt werden dürfen und welche nicht. Da ohne eine Spezifizierung grundsätzlich deine gesamte Seite gecrawlt wird, musst du die Datei nur anpassen, wenn gewisse Inhalte nicht durchsucht werden sollen.
Eine korrekte robots.txt Datei ist aber trotzdem wichtig für die Suchmaschinenoptimierung und kann diese verbessern. Das gilt insbesondere, wenn du eine übermässige Anzahl Crawlinganfragen entdeckst, die deine Seite verlangsamen. Eine gute Ladegeschwindigkeit ist ein Rankingfaktor, weshalb du irrelevante Seiten ausschliessen solltest.
Wichtig zu wissen ist zudem, dass es pro Domain nur eine robots.txt Datei geben darf.
Obwohl es sich um eine simple Textdatei handelt, sollte die robots.txt im ASCII-Format erstellt werden, um von allen Suchmaschinen gelesen werden zu können.
Die Datei selbst besteht immer aus 2 Elementen: Einerseits die Ansprache des User Agenten und andererseits dem Befehl, welche Verzeichnisse gelesen werden dürfen und welche nicht.
Du kannst diese mit einem Texteditorprogramm wie Editor, TextEdit, vi oder Emacs erstellen. Es gibt aber auch zahlreiche robots.txt Generatoren online, mit welchen du die Datei am einfachsten erstellen kannst. Suche dafür einfach nach "robots txt generator" und du erhältst eine grosse Auswahl:
Syntax der robots.txt: Eine Einführung in die Sprache des Web-Crawlings
Hier eine kurze Übersicht darüber, wie eine robots.txt Datei aufgebaut wird.
Jede Information muss auf einer separaten Zeile aufgeführt werden. Du musst immer mit dem User Agent starten, danach kommt eine Zeile für Allow und eine für Disallow.
Ein User Agent ist ein Bot oder ein Programm, welches im Auftrag einer Suchmaschine Websites durchsucht (auch Crawling genannt). Hier kannst du entweder einzelne ansprechen, indem du diese gezielt nennst. Mit User-agent: * kannst du die entsprechenden Befehle dagegen an alle Bots richten.
Hier die wichtigsten User Agents:
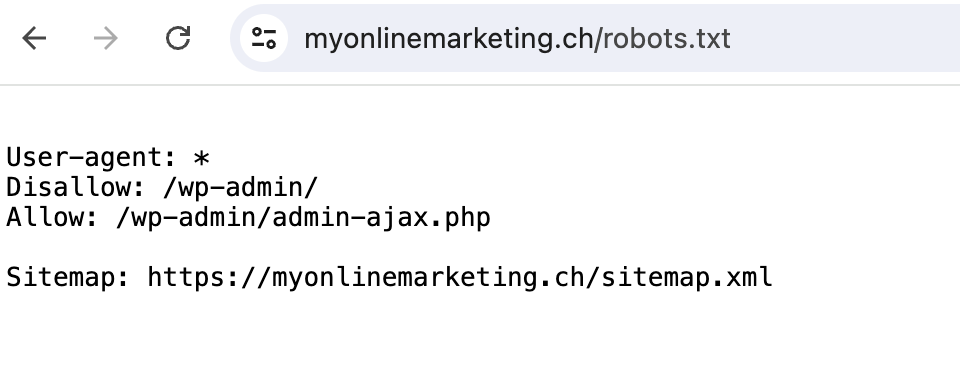
Hier ein Beispiel wie eine solche Datei aussehen kann:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://myonlinemarketing.ch/sitemap.xml
Hier werden sämtliche User Agents angesprochen. Wp-admin, also das WordPress Backend darf nicht gecrawlt werden, die entsprechende php-Datei aber schon und die Sitemap wurde auch verlinkt.
Das Sitemaps-Protokoll, auch Sitemap.xml Datei genannt, enthält die Struktur einer Website. Diese ermöglicht Suchmaschinen durch Crawling zu verstehen, wie die Website aufgebaut ist. Diese ist in der Regel in der robots.txt Datei enthalten, damit die Crawler die URL-Struktur einer Website direkt richtig indexieren können.
Suchmaschinen erwarten die robots.txt Datei unter dem Pfad deine-domain.ch/robots.txt. Daher muss diese im Root-Verzeichnis deiner Seite abgelegt werden. Am einfachsten findest du dieses Hauptverzeichnis, indem du deinen Webhostinganbieter kontaktierst.
Du kannst sie jederzeit aufrufen, indem du nach deiner URL Folgendes eingibst: "/robots.txt." Das würde dann also beispielsweise so aussehen: deineDomain.com/robots.txt
Die häufigsten Fehler in der robots.txt Datei bestehen in der Syntax, beispielsweise durch falsche Schreibweise oder fehlende Leerzeichen.
Wichtig ist beispielsweise, dass du nach der Nennung von Verzeichnissen immer noch einen "/" hinzufügst. Ansonsten wird alles ein- oder ausgeschlossen, welches diese Buchstaben enthält.
Ein weiterer wichtiger Punkt ist, dass Crawler case-sensitive sind. PDF steht demnach für etwas anderes als pdf. Am besten sollte man alle URLs standardmässig klein schreiben, um solche Verwirrungen zu verhindern.
In deiner Google Search Console findest du übrigens auch einen Bericht über die robots.txt Datei, was bei der Fehlersuche helfen kann.
Die robots.txt Datei dient dazu, Suchmaschinen Crawlern zu zeigen, welche Seiten für die Indexierung durchsucht werden dürfen und welche nicht. In der Regel enthält diese Datei auch die XML Sitemap, um die Indexierung durch Suchmaschinen zu erleichtern.
Die robots-Datei selbst wird oft genutzt, um gewisse Verzeichnisse vom Crawling auszuschliessen, wenn eine Website mit Anfragen überlastet ist.
Die Datei muss im Hauptverzeichnis der Domain platziert und "robots.txt" benannt werden. Am besten kontaktierst du deinen Hostinganbieter, um das richtige Verzeichnis zu finden. Die robots.txt verwendet die Syntax des Robots Exclusion Standard (REP) mit Kommandos wie User-Agent, Disallow, Allow, Sitemap.
Möchtest du mehr zum Thema SEO lernen? Dann schau als Nächstes hier rein:
Eine robots txt ist eine Textdatei, die Crawlern mitteilt, welche Verzeichnisse und Inhalte der Website durchsucht werden dürfen und welche nicht.
Die robots.txt Datei wird unter dem Stammverzeichnis der Domain gespeichert. Dein Hostinganbieter kann dir zeigen, wo du diese genau findest.
User Agent * bedeutet, dass alle Crawler Bots angesprochen werden. Disallow bedeutet, dass die nachfolgenden Inhalte nicht durchsucht werden dürfen.